


Keypoints:
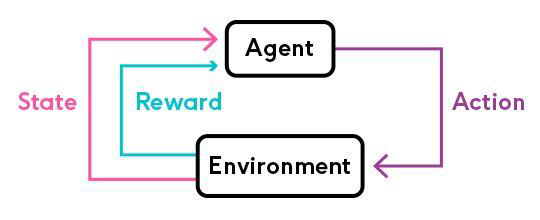
Some problems don’t have a clear answer, but we can still train the agent to get the best result. For example, the game of Go. The agent can’t know the best move in the current state, but it can learn from the experience and get the best move. However, in supervised learning, we need to know the answer of the problem. For example, the image classification problem. We need to know the label of the image to train the model.
Sometimes, there is no clear evaluation of the action. For example, when traing AI to imitate human conservation, we can’t know the best answer. However, we can use machine learning to evaluate the action. For example, we can use a neural network to evaluate the action. The input of the neural network is the state of the environment and the output is the evaluation of the action. Then, we can use the evaluation to train the agent.
The reward of the action may be delayed. For example, when playing chess, the reward of the action may be delayed until the end of the game. Therefore, we need to consider the reward delay when training the agent.
= scalable learning from large, complex datasets = Optimization

